
Introduction to the Darknet
The darknet is a part of the internet that isn't visible to most users. It's home to websites and services that are often used for illegal activities, such as buying drugs or stolen goods. Despite its reputation, darknets can also be used for legitimate purposes - and crawling them with Golang can help you do just that.
What is Tor's role in the Darknet?
Darknet websites are not normally accessible to average internet users. The darknet gives users privacy and protection while also serving as a platform for people looking for non-public internet-based alternatives for entertainment, communication, and business. Millions of people around the world use Tor to browse the web privately.
Additionally, it can enable users to access websites that are otherwise restricted or that are blocked owing to geo-restrictions or other forms of censorship used by governments or other organizations around the world.
Why crawl the Darknet?
- To understand the basic dynamics and operations of the darker parts of the web
- To explore hidden websites and content that can be shared and exchanged confidentially
- To research trends and analyze large datasets from the dark web
- To access data and information that is not easily accessible through the regular internet
- To get insights into suspicious activities that take place behind closed doors within the deep web
Prerequisites for Darknet crawling
Before crawling the darknet, you need to have tor, there are two options to achieve this.
Using tor-privoxy Docker image
A combination of Tor and Privoxy. Download docker-compose.yml and start up the container:
wget https://raw.githubusercontent.com/dockage/tor-privoxy/master/docker-compose.yml
docker compose up -d dockage
dockageInstall Tor natively
- Mac:
brew install tor - Linux:
sudo apt-get install tor
Whether you used the Docker image, or installed Tor natively on your machine, now it's time to check if SOCKS proxy is running: lsof -i :9050

Crawling Darknet with Go
Making a simple HTTP GET request
package main
import (
"context"
"fmt"
"io"
"net"
"net/http"
"golang.org/x/net/proxy"
)
// TorHttpGet function performs an HTTP GET request using the SOCKS5 proxy provided by Tor
func TorHttpGet() {
// dialer is a SOCKS5 dialer that connects to the local Tor instance
dialer, err := proxy.SOCKS5("tcp", "127.0.0.1:9050", nil, proxy.Direct)
// dialContext creates a new Dialer based on dialer that can be used in an HTTP transport
dialContext := func(ctx context.Context, network, address string) (net.Conn, error) {
return dialer.Dial(network, address)
}
// transport is an HTTP transport that uses dialContext to create connections
transport := &http.Transport{DialContext: dialContext, DisableKeepAlives: true}
// cl is an HTTP client that uses transport as its transport layer
cl := &http.Client{Transport: transport}
// req is an HTTP GET request to the specified onion address
req, _ := http.NewRequest("GET", "https://www.bbcnewsd73hkzno2ini43t4gblxvycyac5aw4gnv7t2rccijh7745uqd.onion/", nil)
// resp is the response to the GET request
resp, err := cl.Do(req)
if err != nil {
// panic in case of an error during the request
panic(err)
}
// body is the response body
body, err := io.ReadAll(resp.Body)
if err != nil {
// panic in case of an error while reading the response body
panic(err)
}
// print the response body
fmt.Println(string(body))
}
func main() {
TorHttpGet()
}
You should see the HTML of the BBC's Tor website, of course this is just an example and you can fetch other hidden websites as well.
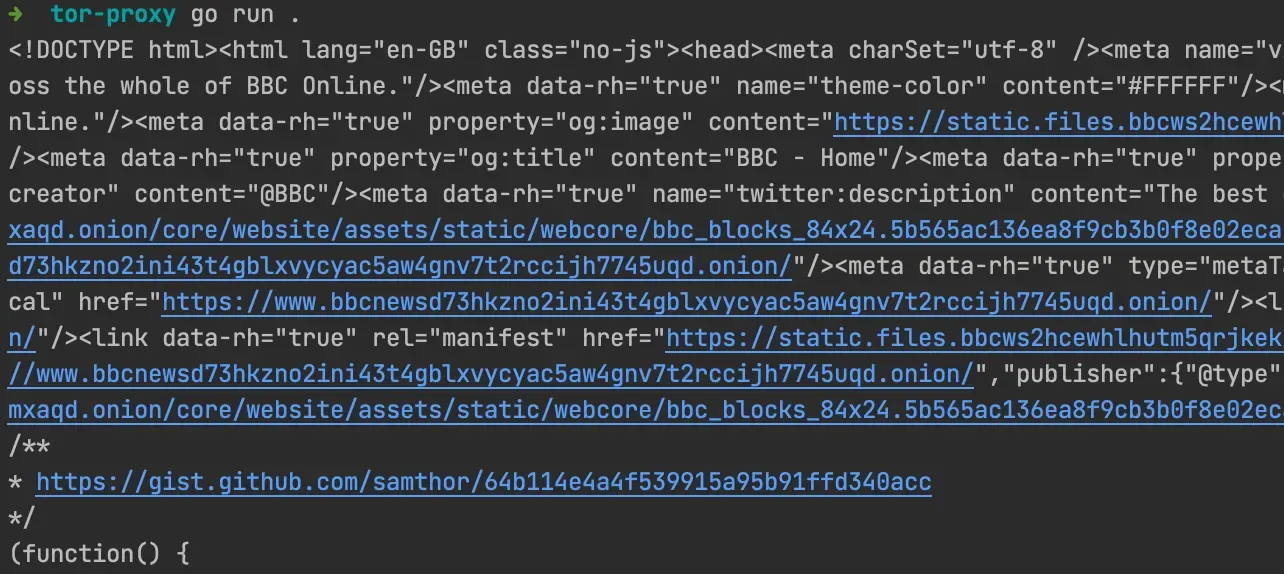
Crawling the Dark Web with Go Colly
Go-Colly is an open source tool that helps with web scraping. It allows users to collect data from websites and automate web browsers for efficient data collection. With Go-Colly, users can capture large amounts of data by easily navigating through web pages and quickly scraping information from them. Go-Colly also provides tools for debugging, testing, and analyzing scraped data.
gocollypackage main
import (
"context"
"fmt"
"net"
"net/http"
"regexp"
"time"
"github.com/gocolly/colly/v2"
log "github.com/sirupsen/logrus"
"golang.org/x/net/proxy"
)
func main() {
// Dialer used for connecting to SOCKS5 proxy at address "127.0.0.1:9050"
dialer, _ := proxy.SOCKS5("tcp", "127.0.0.1:9050", nil, proxy.Direct)
// DialContext creates a new network connection
dialContext := func(ctx context.Context, network, address string) (net.Conn, error) {
return dialer.Dial(network, address)
}
// Transport for sending HTTP requests with dialContext
transport := &http.Transport{DialContext: dialContext, DisableKeepAlives: true}
// Compile a regular expression for allowed paths
allowedPaths := regexp.MustCompile("https://(.*?)bbcnewsd73hkzno2ini43t4gblxvycyac5aw4gnv7t2rccijh7745uqd\\.onion(.*?)$")
// Initialize the collector with default settings
c := colly.NewCollector()
// Set the timeout for requests to 20 seconds
c.SetRequestTimeout(time.Second * 20)
// Use the previously defined transport for sending requests
c.WithTransport(transport)
// Limit the number of requests sent by adding a random delay of 10 seconds
_ = c.Limit(&colly.LimitRule{
RandomDelay: 10 * time.Second,
})
// Handle all links found in HTML pages
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
// Get the URL of the link
url := e.Attr("href")
// Check if the URL matches the allowed path regular expression
match := allowedPaths.Match([]byte(url))
if !match {
return
}
// Check if the URL has been visited before
hasVisited, err := c.HasVisited(url)
if err != nil {
// Log an error if the URL visited check fails
log.Errorf("Failed to check if URL has been visited: %v", err)
return
}
if !hasVisited {
// Visit the URL if it has not been visited before
err := c.Visit(url)
if err != nil {
// Log an error if the URL visit fails
log.Errorf("Failed to visit %s: %v", url, err)
}
}
})
// OnResponse is a callback triggered when a response is received from the server
c.OnResponse(func(e *colly.Response) {
fmt.Printf("Body size: %dKB\n", len(e.Body)/1024)
})
// OnRequest is a callback triggered before sending the request to the server
c.OnRequest(func(r *colly.Request) {
fmt.Print("Visiting: ", r.URL)
})
// Visit starts the crawling process by visiting the first URL. If an error occurs, it will be logged.
err := c.Visit("https://www.bbcnewsd73hkzno2ini43t4gblxvycyac5aw4gnv7t2rccijh7745uqd.onion/")
if err != nil {
panic(err)
}
// Wait blocks until all the crawler's tasks are finished.
c.Wait()
}
Once you run the program, you should see in your console:
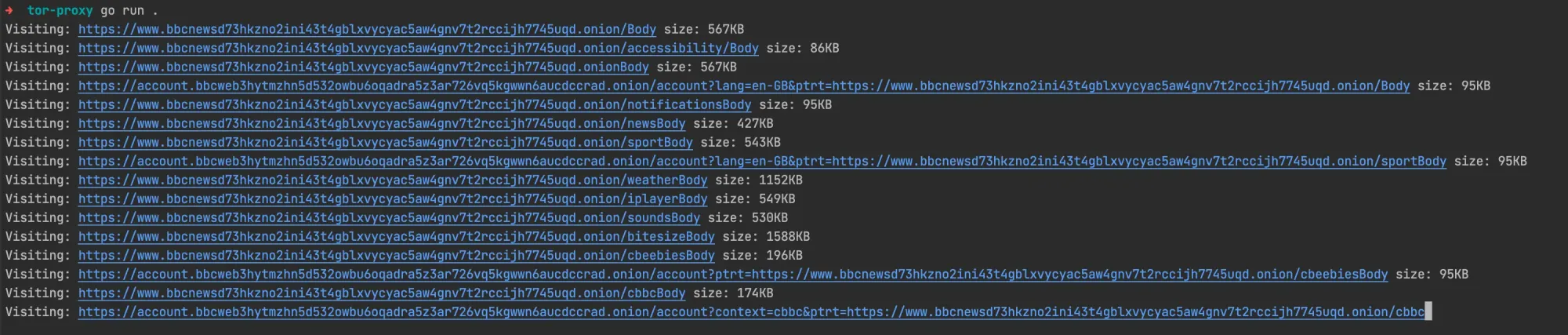
Summary
Crawling darknets with Golang can be a great way to get insights into activities that are taking place on the dark web. With the help of prerequisites like Tor and Go-Colly, developers can easily make requests, scrape data from darknet websites, and analyze large amounts of data for research purposes or other legitimate uses.